
HardZone – Read Recovery Level, así es como tu SSD se recupera de los datos corruptos

No existe ningún medio de almacenamiento que sea completamente inmune a la corrupción de datos, pero gracias a que la tecnología avanza cada vez hay más mecanismos para paliar sus efectos adversos. Ahora, con la especificación NVMe 1.4 introducida en los SSD que hacen uso de este protocolo, se ha habilitado una nueva característica llamada RRL o Read Recovery Level, un mecanismo que ayuda a que el SSD se recupere de errores por datos corruptos de manera automática, y en este artículo te vamos a explicar qué es exactamente y cómo funciona.
Hay muchos factores que pueden influir en el hecho de que se produzcan datos corruptos en un dispositivo de almacenamiento, y una de las ventajas de los SSD es que se pueden integrar mecanismos de protección e incluso de solución en la propia controladora, como sucede con el protocolo NVMe 1.4 que recientemente ha sido publicado. Hoy vamos a ver en profundidad uno de estos mecanismos, quizá el más importante para evitar la corrupción de datos.
Read Recovery Level (RRL) en SSDs NVMe 1.4
La especificación NVMe 1.4 (ojo porque en las versiones anteriores no se integra esta característica de la que os estamos hablando) presenta varias nuevas funciones para ayudar a manejar errores de lectura irrecuperables y datos corruptos, especialmente en configuraciones RAID y escenarios similares donde el sistema host puede recuperar los datos con problemas mucho más rápidamente simplemente sacándolos de otro lugar. Vamos a explicarlo.
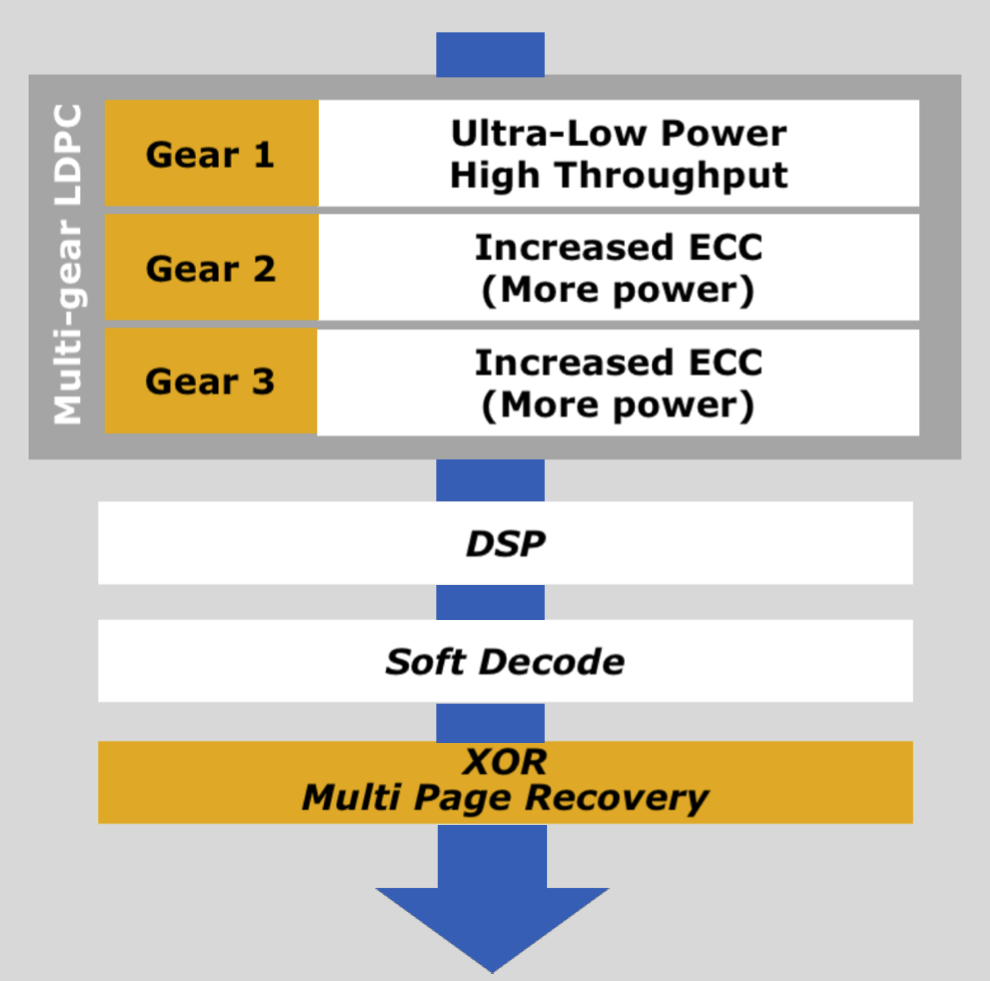
La función Read Recovery Level permite que el sistema host (la controladora, esencialmente) configure la intensidad con la que el SSD debe intentar recuperar los datos dañados cuando se producen problemas. Los SSD suelen tener varias capas de corrección de errores (ECC) como podéis ver en la imagen de arriba, y cada una de las capas es más robusta pero al mismo tiempo más lenta (penaliza el rendimiento) y consume más energía, generando más calor al mismo tiempo.
En un escenario RAID 1 o similar, el sistema host generalmente preferirá librarse de un error rápidamente simplemente intentando leer el mismo dato que ha quedado corrupto en un SSD en otra de las unidades que conforman la configuración RAID, reemplazando el dato corrupto para seguir funcionando normalmente. Hasta ahora el SSD tenía que intentar corregir el problema por sí mismo con los mecanismos ECC, ralentizando el desempeño de la unidad y aumentando considerablemente el consumo de energía y calor generado; además, este método no garantiza la recuperación del dato corrupto, aunque sí funciona bien cuando se producen simplemente errores de lectura.

NVMe ya es compatible con la recuperación de errores por tiempo limitado (TLER, Time Limited Error Recovery), pero esto solo permite que el sistema host ponga un límite al tiempo de manejo de errores en incrementos de 100 ms. Los niveles de recuperación de lectura (Read Recovery Level) permiten que las unidades proporcionen hasta 16 niveles diferentes de estrategias de manejo de errores, pero las unidades que implementan esta función solo deben implementar, en realidad, un mínimo de dos niveles para cumplir con el estándar NVMe 1.4. Esta función está configurada a nivel de conjunto por NVM.
Errores de lectura irrecuperables en los SSD
Para evitar de manera proactiva los errores de lectura irrecuperables, la especificación NVMe 1.4 también añade los comandos Verify y Get LBA Status. El comando Verify es simple: hace todo lo que hace un comando de lectura normal excepto devolver los datos al sistema host, pero con la excepción de que si un comando de lectura devuelve un error, un comando de verificación devolverá el mismo error. Si un comando de lectura tiene éxito, también lo será por lo tanto el comando Verify.
Esto hace posible realizar una limpieza de bajo nivel de los datos almacenados sin que el ancho de banda de la interfaz del host los atasque. Algunos SSD reaccionarán a un error ECC reparable moviendo o reescribiendo los datos degradados o corruptos, y un comando de verificación activará el mismo comportamiento. En general, esto reduce la necesidad de depuración y verificación de suma de comprobación a nivel de sistema de archivos, lo que da como resultado no una mejora de rendimiento, pero sí evitar que éste se vea degradado. Cada comando Verify está etiquetado con un bit que indica si el SSD debe desechar el error rápidamente o intentar recuperar los datos, similar pero anulando la configuración de Read Recovery Level.

Por su parte, la función Get LBA Status permite que la unidad proporcione al host una lista de bloques que probablemente terminen resultando en errores de lectura irrecuperables si se intenta un comando de lectura o verificación sobre ellos; dicho de otra manera, la controladora es capaz de elaborar una lista de datos que son candidatos a fallar y/o dar problemas de antemano, antes de que los errores sucedan.
Es posible que el SSD ya haya detectado errores de ECC durante la exploración automática en segundo plano o, en casos graves, puede informar qué LBA se ven afectados por la falla de un canal o die NAND completo. La función Get LBA Status también se puede utilizar para solicitar a la unidad de SSD que realice un escaneo de los rangos de datos seleccionados antes de devolver la lista de bloques potencialmente irrecuperables.
Cuando el sistema host descubre que hay datos dañados o perdidos, ya sea a través de la función Get LBA Status, al emitir comandos normales de lectura o mediante la función Verify, puede volver a escribir estos datos en el mismo LBA utilizando una copia obtenida de otro lugar (como en un sistema RAID o en una copia de seguridad) y luego continuar usando esos bloques lógicos de manera normal, mientras que el SSD retirará los bloques físicos que estén dañados si es necesario.
Como podéis apreciar, estos son solo algunos de los mecanismos que tienen los SSD para preservar la integridad de los datos cuando suceden problemas en la unidad, y a cada nueva revisión de los estándares (que como en este caso vienen de la mano del estándar NVMe 1.4) se siguen mejorando los mecanismos de detección, protección y solución a los problemas. No obstante, hemos de recordar que a pesar de todo se pueden producir errores irreversibles que terminen por dañar la unidad, nadie está libre de eso (por ahora).
The post Read Recovery Level, así es como tu SSD se recupera de los datos corruptos appeared first on HardZone.