
HardZone – Así ha evolucionado la arquitectura de las GPU AMD Radeon

Las arquitecturas gráficas Radeon de AMD han tenido pocos cambios en los últimos años en comparación con la competencia, ya que de GCN lanzada en 2012 pasamos a RDNA en 2019, la cual ha tenido una renovación reciente con RDNA. Pero, ¿Cuál ha sido la evolución de las GPU de AMD realmente? Sigue leyendo para conocer los cambios de arquitectura de GCN a RDNA 2.
Mientras que NVIDIA ha tenido muchas arquitecturas de GPU distintas en los últimos años, AMD en cambio es tradicionalmente más conservadoras y mantiene una misma arquitectura de GPU con pequeños retoques durante años. Lo vimos con GCN que fue la arquitectura de GPUs de AMD durante varias generaciones y lo estamos viendo con RDNA, donde en los mapas de ruta ya se indica la existencia de una futura RDNA 3 con menos cambios que los que vamos a ver en NVIDIA Lovelace y Hopper.

Pero no vamos a mirar al futuro como Prometeo, sino a ser más de Epimeteo y mirar tanto al pasado como al presente y lo vamos a hacer en el caso de AMD para saber realmente como han evolucionado las diferentes arquitecturas de AMD. La comparación no es por tanto a nivel de generaciones, ni entre tarjetas gráficas entre sí, sino para entender como ha ido la evolución de GCN a RDNA 2.
La evolución de GCN a RDNA
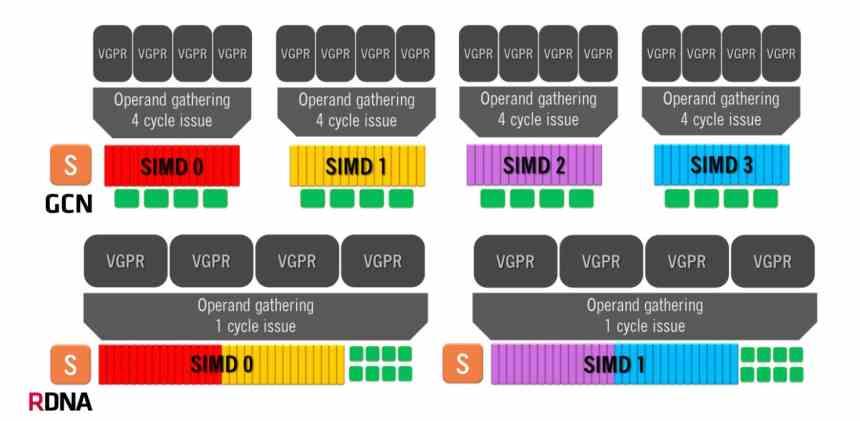
La arquitectura Graphics Compute Next hace uso de una Compute Unit compuesta por 4 grupos SIMD de 16 ALUs cada uno, el cual maneja olas de 64 elementos. Esto se traduce en que en el mejor de los casos, en el que se soluciona una instrucción por ciclo, la arquitectura GCN va a tardar 4 ciclos de reloj por ola de 64 elementos.
En cambio las arquitecturas RDNA tienen un funcionamiento distinto, ya que tenemos dos grupos de 32 ALUs y el tamaño de las olas ha pasado de 64 elementos a 32 elementos. El mismo tamaño que utiliza NVIDIA en sus GPUs, por lo que ahora el tiempo mínimo por ola es de 1 solo ciclo debido a que tenemos las 32 unidades de ejecución funcionando en paralelo. Aunque la media de instrucciones resueltas sigue siendo de 64, se trata de una organización mucho más eficiente.
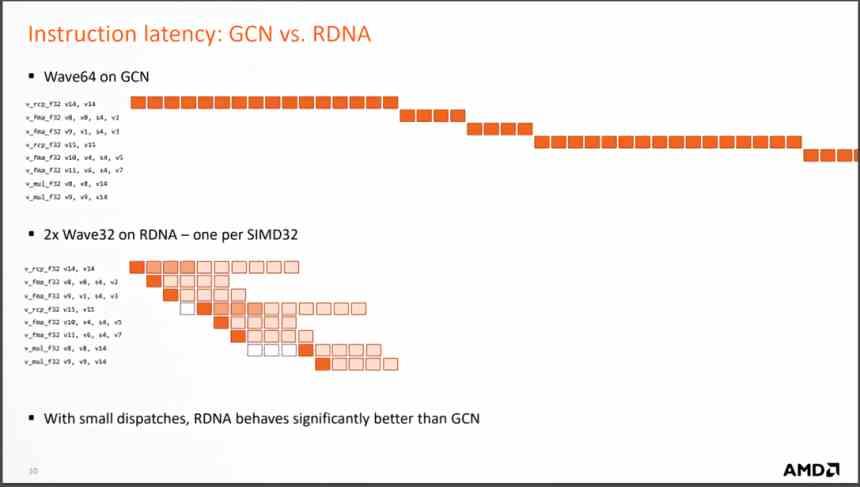
Pero el cambio más importante es el cambio a la hora de ejecutar las instrucciones que llegan de cada ola, ya que RDNA las resuelve en muchos menos ciclos, lo que se traduce en que la media de instrucciones por ciclo que se resuelven es mucho más grande y con ello el IPC medio aumenta.
¿En qué se traduce esto? Pues en el hecho que pasan a ser necesarias muchas menos Compute Units para conseguir el mismo rendimiento, menos Compute Units significan una GPU más pequeña para conseguir el mismo rendimiento. En realidad AMD empezó a realizar el diseño de RDNA tan pronto como vieron que una GTX 1080 con «solo» 40 SM barría el suelo con la AMD Vega de 64 Compute Units. Ese fue el punto en que vieron como la arquitectura GCN no daba más de sí.
Evolución del sistema de cachés

Para entender la evolución de una arquitectura gráfica a otra, es importante conocer el sistema de cachés y como ha ido evolucionando de una generación a otra.
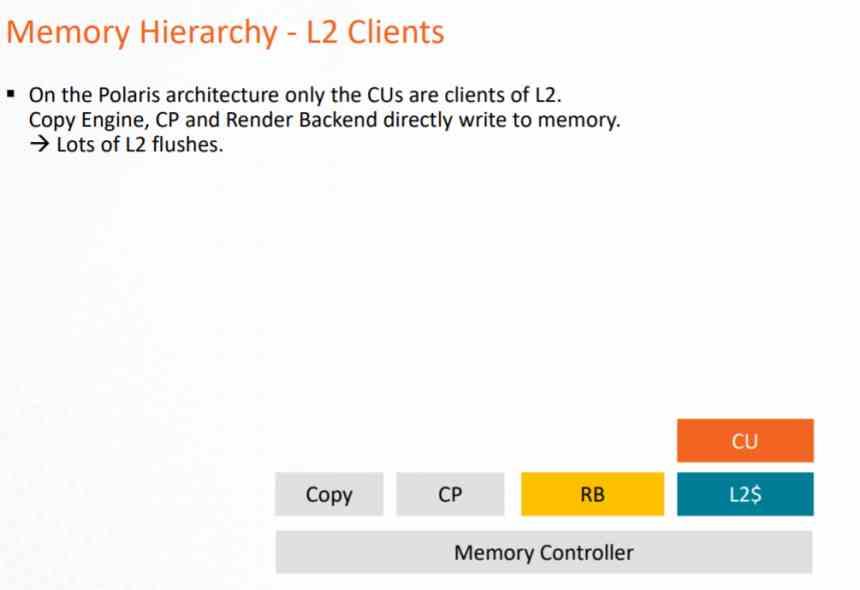
En la arquitectura GCN el sistema de cachés solo podía ser utilizado por el pipeline de computación, debido a que los Pixel Shaders al ejecutarse exportan a los ROPS y estos directamente sobre la VRAM, lo cual supone una carga muy grande sobre la VRAM y un consumo de la energía muy grande.

Este problema se solucionó al final de la vida de dicha arquitectura con AMD Vega, donde tanto los ROPS como la unidad de rasterizado se comunicaron a la caché L2 con tal de reducir la carga en el bus de datos hacía la VRAM. Pero especialmente para aplicar el DSBR o Tiled Caching, el cual consiste en adoptar el Tile Rendering, pero de manera parcial y que NVIDIA ya había adoptado en Maxwell.

En RDNA el cambio principal fue hacer que todo pase a ser cliente de la L2, pero añadiendo una cache intermedia que es la L1, de esta manera la nomenclatura cambio.
- La caché L1 incluida en las Compute Units pasa a ser la caché L0, con la misma funcionalidad.
- Se añade una caché L1, la cual es intermedia entre la caché L0 y la caché L2.
- Todos los elementos de la GPU ahora pasan por la caché L2.
Toda operación de escritura se realiza sobre la caché L2 de manera directa, mientras que la caché L1 es de solo lectura. Esto se hace para evitar la implementación de un sistema de coherencia más complejo en la GPU que ocuparía una gran cantidad de transistores. Ya que gracias a la caché L1 de solo lectura puede otorgar los datos a varios clientes dentro de la GPU al mismo tiempo.
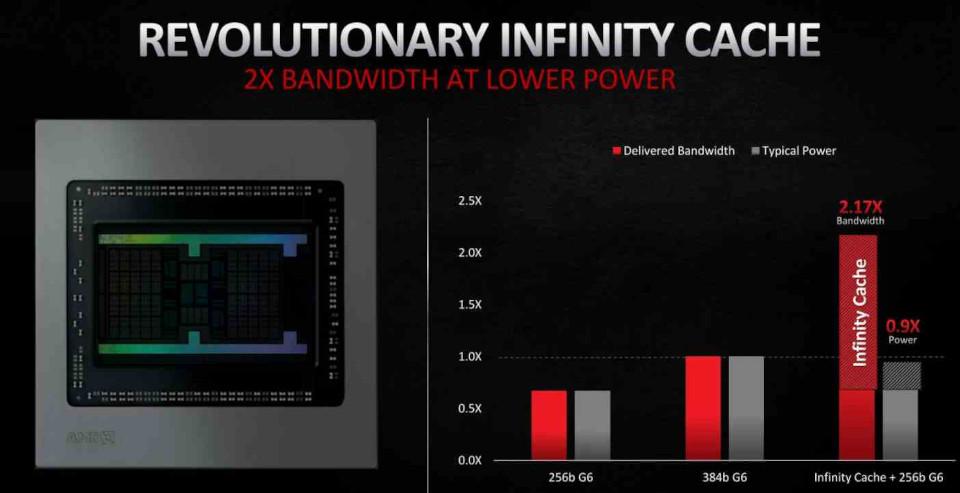
En RDNA 2 la inclusión más importante ha sido en forma de la Infinity Cache, la cual actúa no como una caché L3 convencional sino como una Victim Cache, adoptando las líneas de caché descartadas por la cache L2, de esta manera se evita que esos datos caigan a la VRAM, lo que facilita su recuperación y como veremos más adelante reduce el coste energético de ciertas operaciones, lo que la convierte en una pieza clave de cara a las mejoras en RDNA 2.
La localización de los datos, es importante de cara al consumo energético. Ya que cuanto más grande es la distancia que tenga que recorrer un dato entonces más grande es el consumo energético. Ahí es donde entra la Infinity Cache, la cual permite operar con los datos con un consumo mucho menor.
RDNA 2, una evolución menor

RDNA 2 en cambio es una versión levemente mejorada de RDNA y no un cambio menos radical, por lo que AMD habría vuelto a la estrategía de ir lanzando mejoras continuas sobre una misma arquitectura. Se dice que AMD lanzo RDNA durante la segunda mitad de 2019 como una solución temporal mientras terminaban de pulir RDNA 2 que es la versión ya terminada de la arquitectura y totalmente compatible con DirectX 12 Ultimate.
Si hablamos en términos de computación, RDNA 2 no tiene ninguna ventaja respecto a RDNA y las mejoras se han dado más bien en elementos ajenos a la parte encargada de ejecutar los shaders.
- Se ha mejorado la unidad de texturas y se le ha añadido una unidad de intersección de rayos para el Ray Tracing.
- Los ROPS y las unidades de rasterizado han sido mejoradas para soportar Variable Rate Shading.
- La GPU soporta ahora mayores velocidades de reloj.
- Inclusión de la Infinity Cache para reducir el consumo energético de ciertas instrucciones.
Una de las claves para poder alcanzar una mayor velocidad de reloj en un procesador es hecho de super-segmentar el pipeline, pero esto es algo que no se puede realizar en la unidad shader de una GPU de la misma forma que en una CPU. Por lo que ha hecho AMD a nivel interno es medir el consumo energético de cada instrucción que puede realizar la Compute Unit. Dado que hay instrucciones que consumen menos energía se pueden ejecutar a mayor velocidad de reloj este permite alcanzar pico de velocidad más altos a la hora de ejecutarlas.
The post Así ha evolucionado la arquitectura de las GPU AMD Radeon appeared first on HardZone.